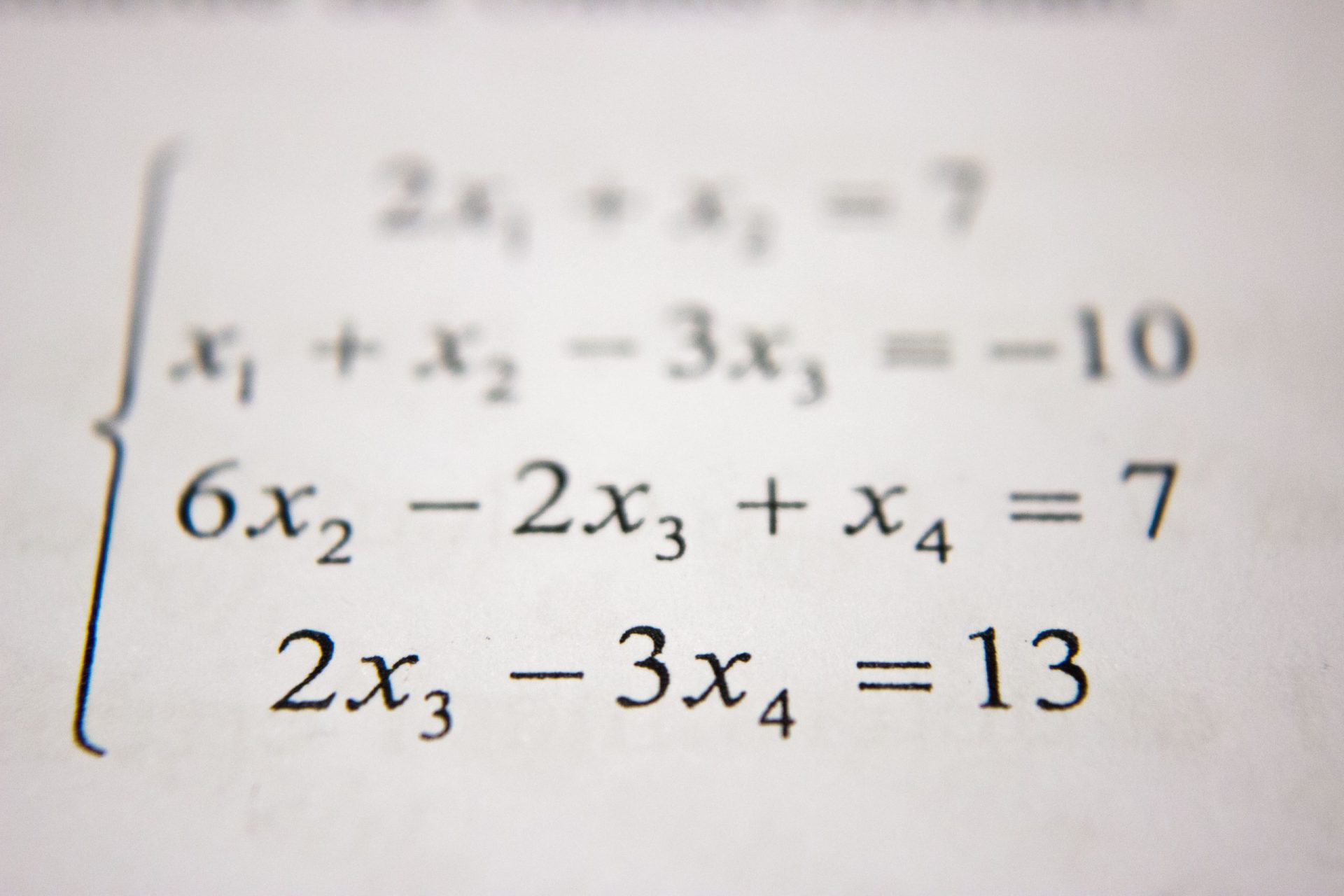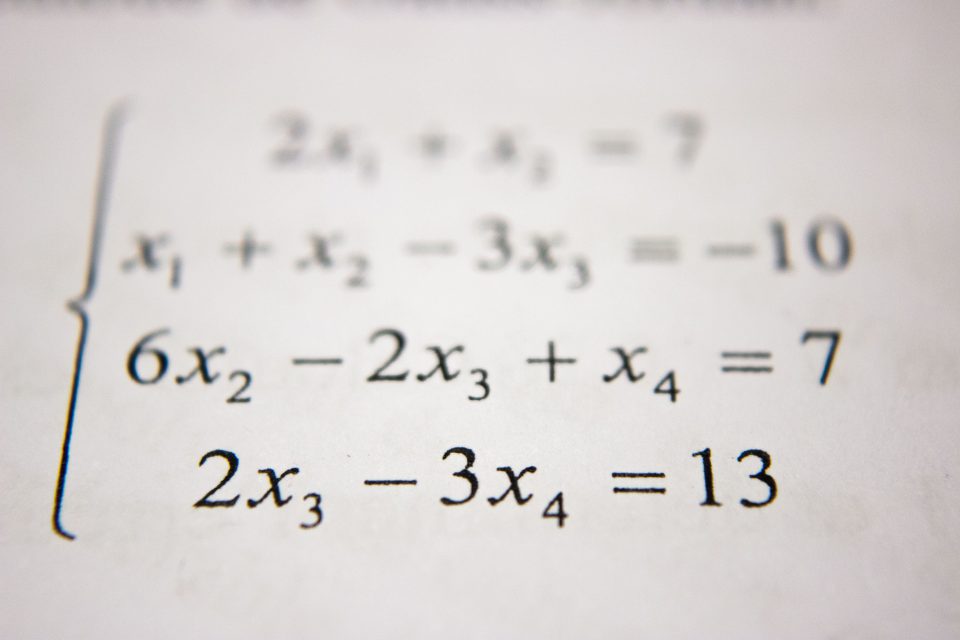
Algorithms are sets of step-by-step instructions that tell a computer what to do. Algorithms can also be designed to learn by themselves instead of only following instructions.
For example, pretend you want to write an algorithm that tells the search engine how to identify pencils. So you feed the algorithm data — millions of photos correctly labeled as pencils. The algorithm can then detect other pictures of pencils by comparing it to a set of attributes it has “learned” from the data (the millions of pencil images) you have fed it.
But an algorithm is only as good as the data it learns from. The more data an algorithm is trained on, the more accurate the results will be. But if there’s not enough data, the algorithm will have “blind spots.”
That’s because behind every algorithm, there’s a person, and that person’s set of values and cultural intelligence will influence what data the algorithm is trained on and how the computer learns. Thus, if Amazon teaches its facial recognition software to recognize human faces but has used mostly Caucasian males as its main dataset, then it would make sense if the software didn’t recognize Black female faces. Because the dataset did not include enough Black female faces, the machine could not learn what they looked like, and therefore the software was unable to accurately recognize Black women.
This is a classic example of algorithmic bias, where the algorithm was not trained with enough related data in order to yield accurate results.
Click continue to read more.